![Nandu Anilal: Investing in data [2021]](https://canaan.com/rails/active_storage/blobs/eyJfcmFpbHMiOnsibWVzc2FnZSI6IkJBaHBBaklGIiwiZXhwIjpudWxsLCJwdXIiOiJibG9iX2lkIn19--cde2a2c31a772e012c00d8f71a2bf146012ecb2d/8.png)
2020 was a big year for data infrastructure. Snowflake rocked our world, suddenly growing from a $12B valuation in February to $80B in the public markets only months later. The growth and scale of the business validated the underestimated significance of data infrastructure in today’s world. Following its success, we are already seeing other companies command significant step-up valuations (Databricks just raised at $28B). While large names like Snowflake and Databricks command headlines, there's also a variety of reasons to be excited about data infrastructure at the early stage. In this post, I cover a few topics around investing across the data landscape:
1. Rise of the Data Company
2. Changes in Distribution
3. Data Warehouse vs Data Lakes
4. Data Investment Themes
***
Rise of the Data Company
One of the reasons I'm most excited about companies building in and around data is that I think we're seeing a powerful flywheel begin to run which will ultimately expand the market for data tooling:
-
More data: the long-running secular trend is that storage has become cheaper so we can digitize more information and processes
-
More data talent: we are now seeing more talent flowing towards growing areas like data science, data engineering, analytics allowing for more companies to build around the data they've collected
-
More data companies: with this data and data talent, even the average business is able to start leveraging data for business-critical applications rather than ad hoc analytics
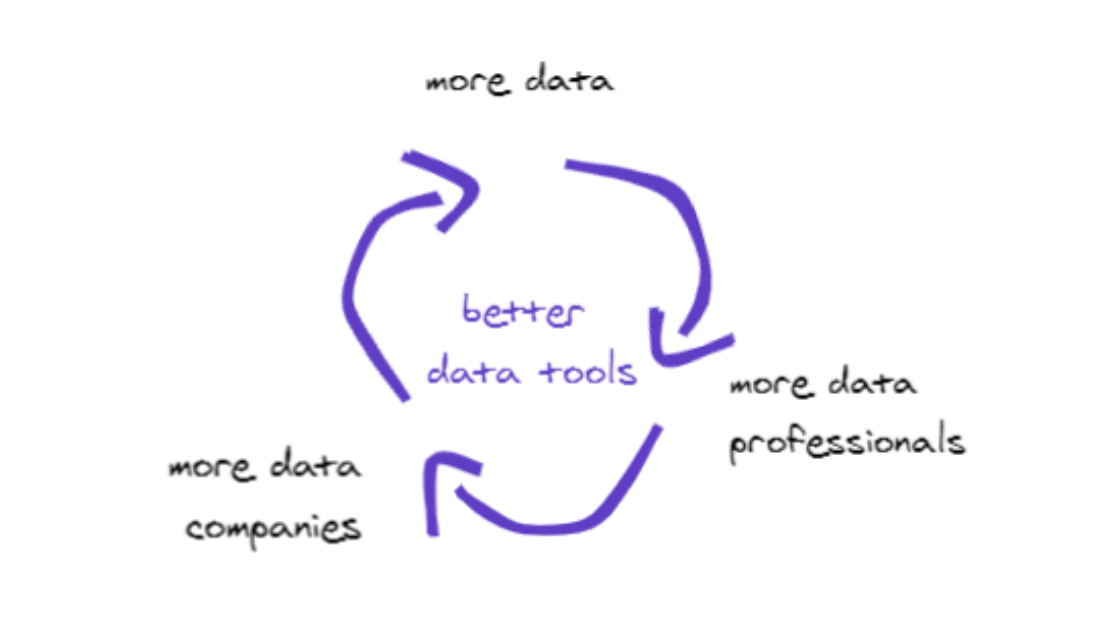
It used to be that only the Ubers of the world were leveraging data to drive product differentiation, but that has changed as talent has become more accessible. As a result, we're now seeing traditionally offline businesses slowly become data companies.
I believe this self-reinforcing loop will continue to drive more investment into proper data tooling very similarly to how the past decade has resulted in an explosion of developer tool spend. With the context set on why I am excited about the market as a whole, I want to highlight what’s changing in how data infrastructure companies are going to market.
Changes in Distribution
On the distribution side of the equation, a couple interesting things have happened:
1/ Open Source Enabling Bottoms-Up Adoption
At this point, open source is well into the mainstream, with 77% of enterprises expect to increase their open source usage in the coming years. Many of these projects still originate inside large high-tech companies, but everyone from startups to established incumbents are leveraging open source today.
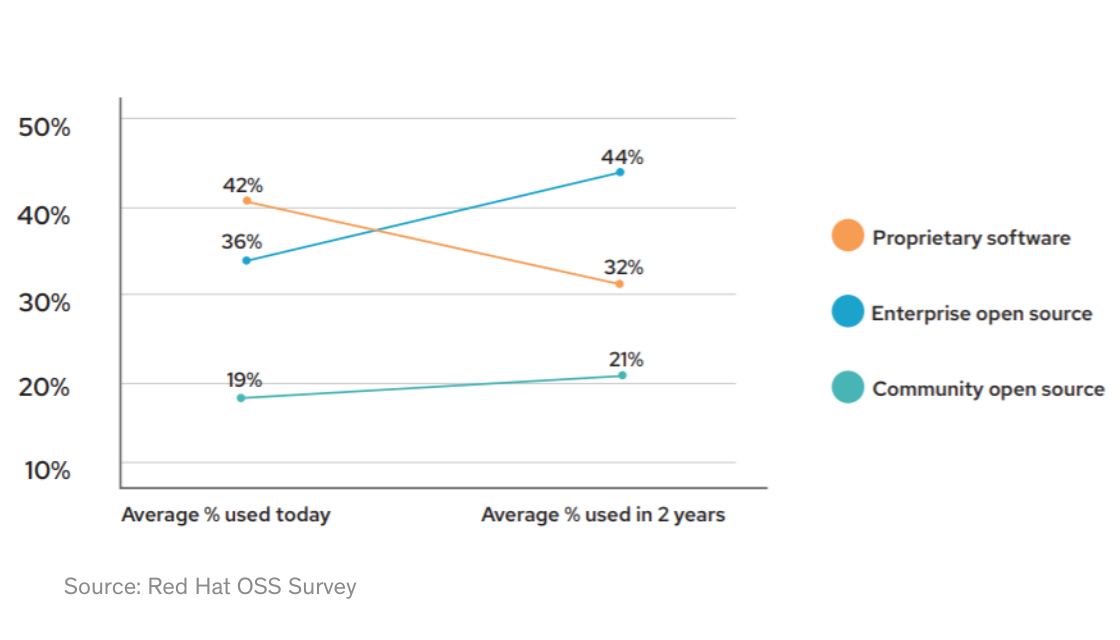
While open source is not specific to any one domain, it is particularly compelling in the context of data infrastructure. Open source removes the friction of trying new software, shifting more decision-making power into the hands of users rather than managers. It allows data engineers, software developers, etc to solve problems with whatever tool fits the job rather than relying on managers to proactively purchase the right tools. While this comes with its unique set of challenges around monetization, it unlocks a community-led growth model which can be extremely powerful.
2/ Partnering with Established Ecosystems
Perhaps a result of the explosive growth seen by Snowflake this year, I've seen more startups build on top of their ecosystem. While the demand for cloud data warehouses is well known, newer infrastructure startups are attempting to cement their position into the data stack by partnering with Snowflake. Products like Fivetran and DBT have done an especially good job leveraging Snowflake as a common anchoring point, who is happy to have startups build around them.

In many ways, I think this highlights the importance of marketing within the increasingly crowded data infrastructure landscape. As large new companies are built, there's an opportunity position yourself in relation to them. In the future, I suspect we see more of this from those building AI/ML tooling around the Databricks ecosystem.
Heading to the LakeHouse
One of the big questions surrounding the data landscape is whether the future of data revolves around the data warehouse or the data lake?
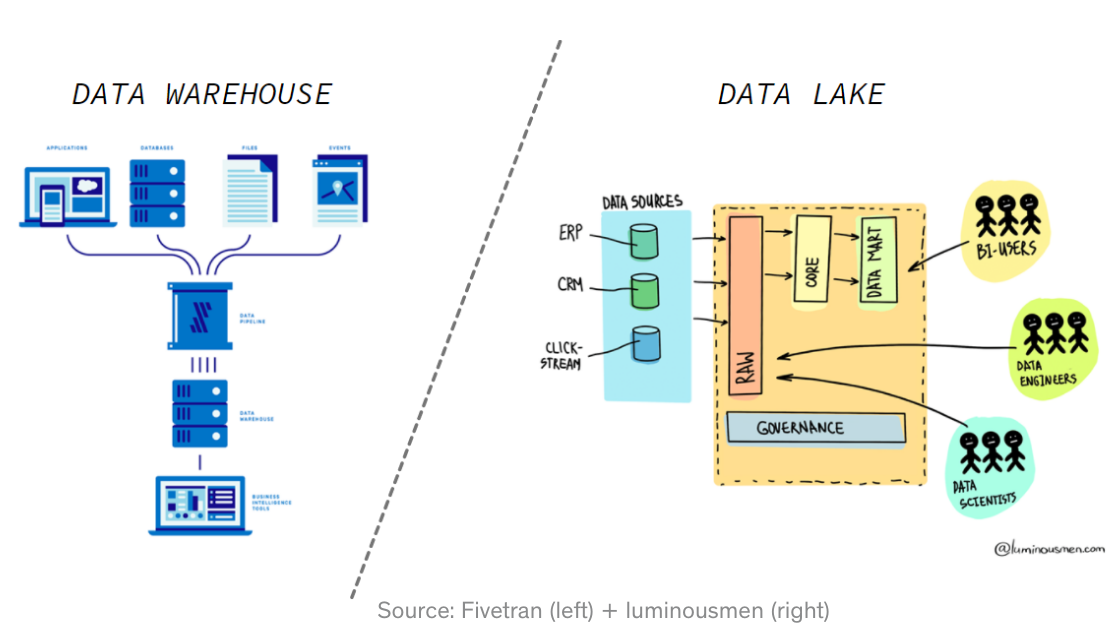
On one hand, a data warehouse-centric architecture flows fairly linearly. Data is collected from various places, moved into the warehouse, transformed, and made broadly accessible in a BI/visualization tool. The major shortcoming is that the data warehouse is not the cheapest way to store data and it isn't optimal for unstructured data. As such, it has been primarily associated with analytics rather than data science.
On the other hand, a data lake-centric architecture starts by dumping virtually all raw data into a very low cost data store (ie the lake) and then portions of that data are moved into analytics or data science workflows. While it's great to have virtually all of your data accounted for, it's not always easy to navigate or immediately useful.
In the long-run, I think these two architectures end up looking pretty similar. The data warehouse will attempt to accommodate data science workflows while the data lake will attempt to better suit analytics use cases. That has given rise to what's being dubbed the "LakeHouse" — a best of both worlds scenario.
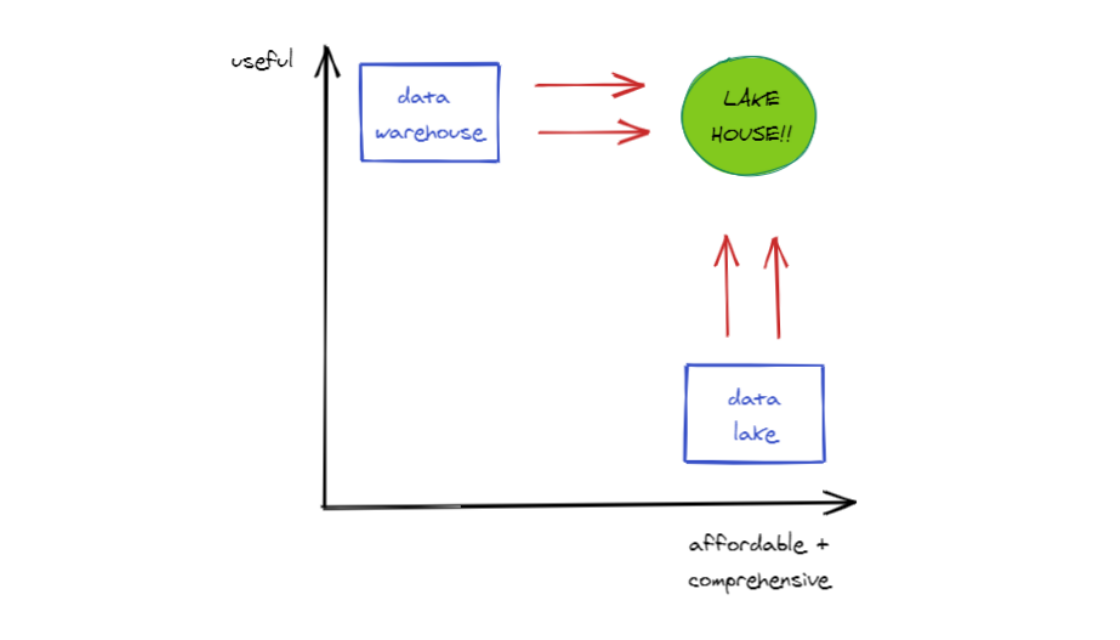
And this transition has already began:
-
Databricks released Delta Lake, an open source project to add more functionality and reliability to the lake
-
Snowflake is increasingly integrating and partnering with the existing ML tech stack with its Data Cloud
This is to say that I think the data warehouse vs data lake argument doesn’t seem to be winner-take-all and that we’re likely to see lots of innovation around these two views.
That brings me to the main point of this article — 4 themes that I think are really interesting places to build companies today.
Investment Themes for 2021
1/ Data Transport
If you believe that the data lakes and data warehouses of the world will continue to be an important part of the architecture of the future, then it follows that there will be a need to move that data to and from those points.
-
Routing from inputs: This comes in a couple flavors. A customer data platform (eg Segment) takes customer-generated data and provides a unified customer view that can be moved into any other destinations. More recently, Fivetran helps you connect data from various applications into a data store like Snowflake. Are there specific types of data that warrant new companies to be built here?
-
Routing to outputs: In the earlier-stage, companies like Census help move data from a centralized warehouse into the various places it needs to go (sales, customer support, etc). As data gets centralized in the warehouse, there's more opportunities to bring that structured data elsewhere like Seekwell bringing SQL directly into spreadsheets. As information becomes centralized in a warehouse, how does the relationship between these data destinations and the warehouse change?
2/ Data Engineering Automation
One of the fastest growing jobs (in the world of already fast growing tech jobs) is the data engineer. I believe a key reason that there's so much demand is because data engineering gets pulled in as an intermediary between users of data and the systems where they reside. Removing this friction ultimately will unlock tons of value for end users.
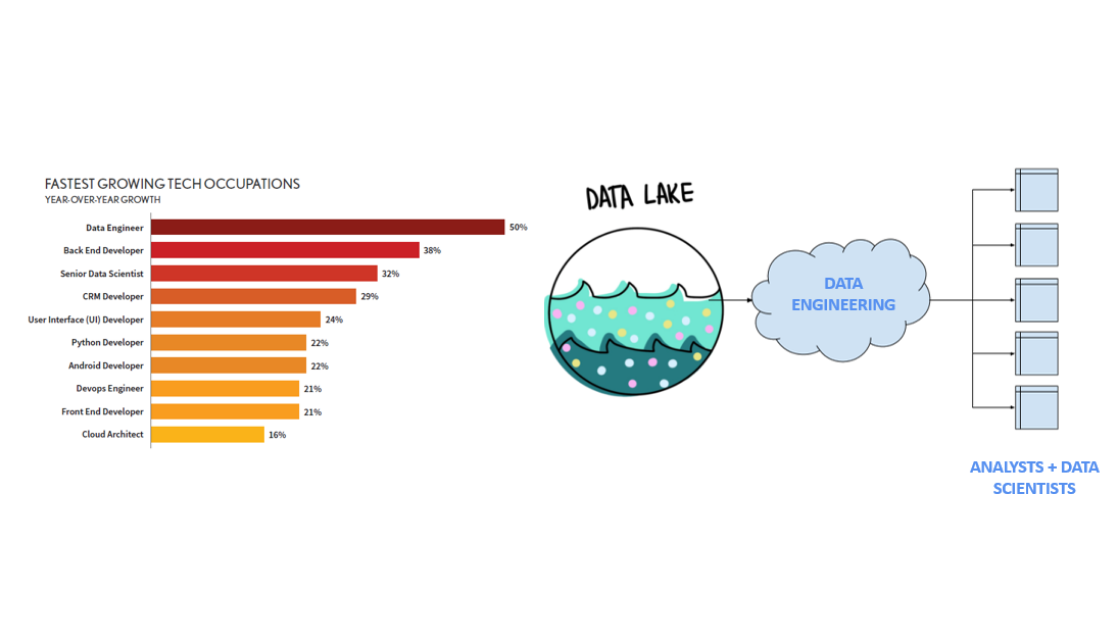
There’s two ways to address this pain point:
-
Give data engineers better orchestration tools: Open source projects like Airflow and companies like Prefect are automating much of the complexity of building and running data pipelines. These tools enable stretched-thin data engineers to become more efficient and less inundated by repetitive work.
-
Give non-data engineers easier-to-use tools: On the other hand, companies like Upsolver are democratizing data engineering by swapping out complex pipeline work with a visual interface and SQL tooling that data analysts and data scientists are familiar with. This allows these data users to more independently jump into their workstreams.
3/ Fixing Data Swamps
There's basically no end to the amount of data that companies are going to be storing. Data storage and compute goes down and companies end up storing everything. There will continue to be large businesses built around demystifying the data lake and make it less of a data swamp. Companies like Collibra and Alation have already built large businesses helping you catalog this data. More recently, BigID has come at this from more of a data privacy and security angle. I think we'll continue to see different versions of companies that are making large volumes of messy data more useful.
-
Better table formats: There's a number of open source projects like Apache Iceberg, Apache Hudi, and Databricks' Delta Lake that are all adding reliability to data lakes with features like ACID transactions and more.
-
Data observability: Companies like Databand are providing observability for data engineers to see how data flows through various systems and helping them trouble shoot pipeline issues. Monte Carlo takes a different approach here focused on reducing data downtime as data moves through an enterprise architecture.
4/ Opening up the ML Black Box
As data moves to more customer-facing ML applications, there's going to be more pressure to understand what is happening. The go-to example of this was Uber because it essentially relied on ML for all of its key components: matching, pricing, batching, etc. While ML can provide a significant boost to business metrics, there’s typically been challenges in unpacking what’s going on inside the model for various stakeholders. There's a few angles to support these AI-first company builders:
-
Performance: Are models at optimal performance? This bucket of companies is tackling everything from data quality to drift and are primarily focused on the data scientist or ML engineer.
-
Explainability: What is happening inside the black box of ML? This will especially important to functions outside of data science like customer support, business analysts, etc.
-
Governance: Are these models compliant and fair? While GDPR has become a central concern for the modern enterprise, we are only starting to see the impact of regulations like SR 11-7 on how compliance and risk teams manage model risk.
By no mean is this an exhaustive list, but serves as a jumping off point for my own thinking around data infrastructure.
If you're building, investing, or generally interested in this space, I'd love to chat. Feel free to shoot me an email at nanilal@canaan.com or find me on twitter @nanduanilal.
Lastly, thanks to a few folks for thinking through some of these points with me and reading drafts: Rayfe, Rak, Jessica, Nikki.